1. 재현 가능성
재현 가능성이란 동일한 연구나 실험을 반복했을 때 일관된 결과가 나오는지 여부를 말하는 것으로 연구의 신뢰성을 높이는 중요한 요소이다. 결과가 재현되지 않는다면 해당 가설의 신뢰도가 떨어진다.
최근 'p값을 사용하지 않는 것이 좋다'와 '유의 수준을 0.05에서 변경하는 것이 좋다' 두 가지로 값에 대한 논쟁이 두드러지고 있다.
- 재현성 위기 원인
1) 실험 조건을 동일하게 조성하기 어려움
완전 동일하게 다시 똑같은 실험을 수행하는 것이 쉽지 않으며 가설검정 자체도 100% 검정력을 가진 것이 아니기 때문에 오차가 나타날 수 있음
2) 가설 검정 사용방법에 있어서 잘못됨
p값이 0.05가 유도되게끔 조작하는 것이 가능(p해킹)하며 실제로는 통계적으로 아무 의미가 없음에도 의미가 있다고 해버리는 1종 오류를 저지를 수 있음
2. p-해킹
데이터 분석을 반복하여 p-값을 인위적으로 낮추는 행위를 말한다. 유의미한 결과를 얻기 위해 다양한 변수를 시도하거나 데이터를 계속해서 분석하는 등의 방법을 포함한다.
p-해킹은 데이터 분석 결과의 신뢰성을 저하시키기 때문에 여러 가설 검정을 시도하여 유의미한 p-값을 얻을 때까지 반복 분석하는 것을 조심해야 한다. 또한, p-해킹은 유의미한 결과를 얻기 위해 p-값이 0.05 이하인 결과만 선택적으로 보고하는 행위를 조심해야 한다.
데이터의 수를 늘리다 보니 특정 데이터 수를 기록할 때 잠깐 0.05 이하를 기록함으로 이를 바탕으로 대립가설 채택하는 것 즉, 결과를 보며 데이터 개수를 늘려서는 안 된다.
가능한 가설을 미리 세우고 검증하는 가설검증형 방식으로 분석을 해야 하며 만약 탐색적으로 분석한 경우 가능한 모든 변수를 보고하고 본페로니 보정과 같은 방법을 사용해야 한다.
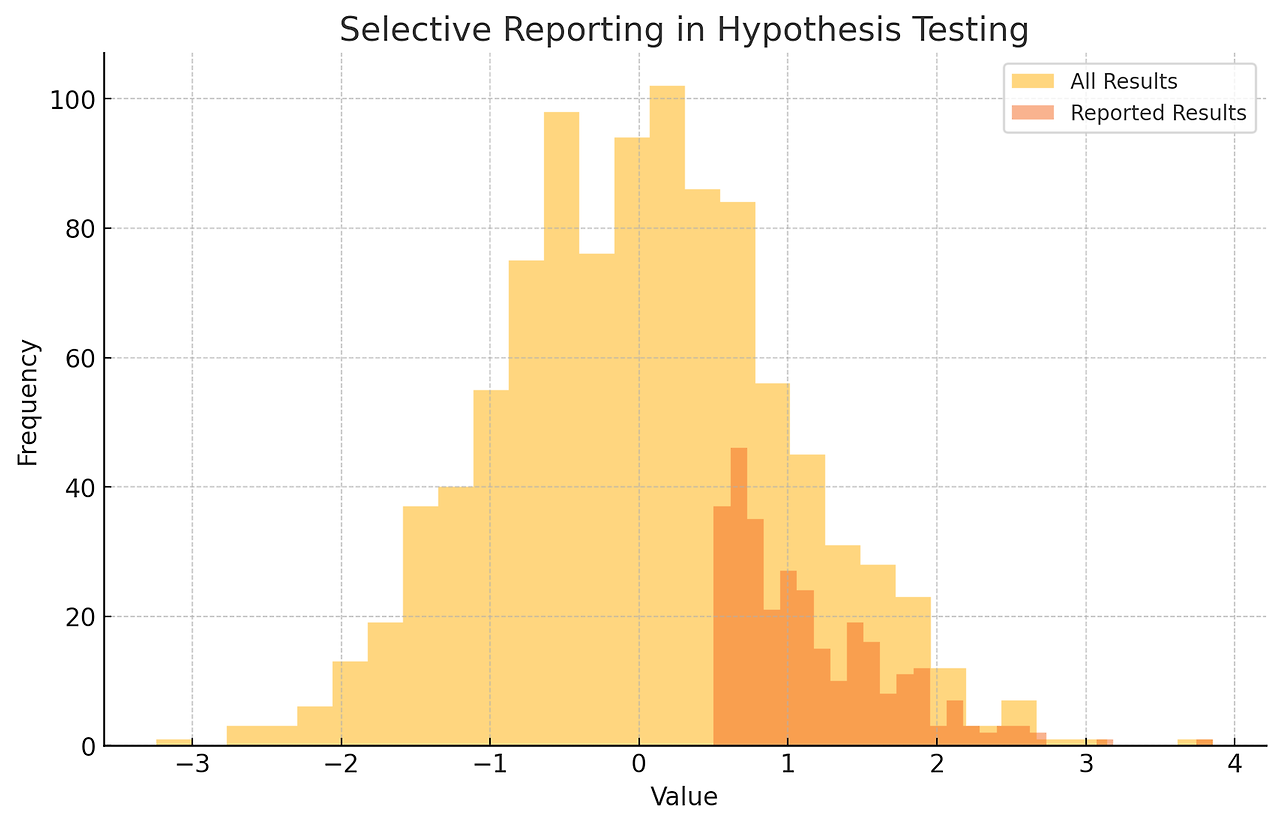
3. 선택적 보고
유의미한 결과만을 보고하고 유의미하지 않은 결과는 보고하지 않는 행위를 말한다. 이는 데이터 분석의 결과를 왜곡하고 신뢰성을 저하시킨다.
전체 결과와 보고된 결과의 분포가 다르면 선택적 보고의 가능성을 시사한다.
결과를 보면서 가설을 다시 설정했는데 마치 처음부터 설정한 가설이라고 말하는 것 또한 선택적 보고에 해당한다.
4. 자료수집 중단 시점 결정
데이터 수집을 언제 멈출지 결정하는 것은 결과에 영향을 미칠 수 있으므로 데이터 수집을 시작하기 전 언제 수집을 중단할지 명확하게 결정해야 한다. 그렇지 않으면 원하는 결과가 나올 때까지 데이터를 계속 수집할 수 있고 이는 결과의 신뢰성을 떨어뜨리기 때문에 사전에 정해진 계획에 따라 자료수집을 중단해야 한다.
# 데이터 수집 예시
np.random.seed(42)
data = np.random.normal(0, 1, 1000)
sample_sizes = [10, 20, 30, 40, 50, 100, 200, 300, 400, 500]
p_values = []
for size in sample_sizes:
sample = np.random.choice(data, size)
_, p_value = stats.ttest_1samp(sample, 0)
p_values.append(p_value)
# p-값 시각화
plt.plot(sample_sizes, p_values, marker='o')
plt.axhline(y=0.05, color='red', linestyle='dashed', linewidth=1)
plt.title('자료수집 중단 시점에 따른 p-값 변화')
plt.xlabel('샘플 크기')
plt.ylabel('p-값')
plt.show()
5. 데이터 탐색과 검증 분리
데이터 탐색을 통해 가설을 설정하고 이를 검증하기 위해 별도의 독립된 데이터셋을 사용하는 것을 말한다. 이는 데이터 과적합을 방지하고 결과의 신뢰성을 높여준다.
데이터 셋을 탐색용과 검증용으로 분리하여 사용할 때 검증 데이터는 철저하게 탐색 데이터와 구분되어야 한다. 데이터 탐색과 검증을 분리하면 탐색 과정에서 발견된 패턴이 검증 데이터에서도 유효한지 확인 가능하다.

from sklearn.model_selection import train_test_split
# 데이터 생성
np.random.seed(42)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 데이터 분할 (탐색용 80%, 검증용 20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 탐색용 데이터로 예측
y_train_pred = model.predict(X_train)
# 검증용 데이터로 예측
y_test_pred = model.predict(X_test)
# 탐색용 데이터 평가
train_mse = mean_squared_error(y_train, y_train_pred)
train_r2 = r2_score(y_train, y_train_pred)
print(f"탐색용 데이터 - MSE: {train_mse}, R2: {train_r2}")
# 검증용 데이터 평가
test_mse = mean_squared_error(y_test, y_test_pred)
test_r2 = r2_score(y_test, y_test_pred)
print(f"검증용 데이터 - MSE: {test_mse}, R2: {test_r2}")'내배캠 - TIL > Python' 카테고리의 다른 글
| [TIL] Python 챌린지 - 5회차 (0) | 2024.08.07 |
|---|---|
| [TIL] Python 베이직 - 6회차 (0) | 2024.08.06 |
| [TIL] 통계학 기초 - 5주차 (0) | 2024.08.05 |
| [TIL] 통계학 기초 - 4주차 (0) | 2024.08.02 |
| [TIL] Python 챌린지 - 3, 4회차 (0) | 2024.08.02 |